Why Benchmark your AI Model against Humans?
- July 1, 2020
- Posted by: admin
- Category: AI

Is your AI model as good as a human? But should you even care if your machine or deep learning classifier is as good as a human. But why? And how do you quantify human-level performance?
What is human-level performance?
When I first started working as a TPM (Technical Program Manager) on AI (Artificial Intelligence) models, it seemed my only value was that of a taskmaster: make sure annotation requests from data scientists get annotated correctly and on time so there was enough training and test data to build classifiers. But I quickly realized that aiming for an incremental performance improvement, while an acceptable goal, could be significantly improved. We had to raise the goal higher to ensure all our classifier models were achieving human level performance for that narrow task. But what is human level performance?
Human-level performance for AI models, whether machine or deep learning models, means that the algorithm performs a very specific task at the same level of performance as a person. As an example, if a doctor is responsible for classifying if skin lesions are cancerous or not, he may be correct 90% of the time. If your cancer detection algorithm achieves an accuracy of 90%, then it has achieved human-level performance for detecting skin cancer.
Perhaps now, you can build a mobile app around this cancer detection algorithm and sell it to millions of people for a few dollars and advertise it as being as good as an oncologist. However, this algorithm will be useless in identifying types of rash: is it a rash because of a flea bite, contact dermitis or eczema? So this is about narrow AI and not general AI. In other words, just like people specialize in a narrow field, the app is a specialist and not a generalist. And its performance can only be measured for that narrow task.
Human-level Performance for Object Detection
Take the example of an after-market car product for collision avoidance such as Mobileye 8 connect that was built in Jerusalem and purchased by Intel for $15.3 billion for their AI products and expertise. The classifier in the accessory uses computer vision and deep learning models to detect objects in front of it. This $1,000 accessory attaches to the interior of your car’s windshield and acts as a second pair of eyes for you while driving. It starts beeping if you get too close to cars, pedestrians and cyclists, alerts you when you drift out of your lane and even alerts you if you are going too fast and don’t have enough headroom to stop your car before hitting the car in front of you. It’s a cool product that works well in a daylight situations.
But once, on a visit to an international client, I was driving a rental car fitted with this accessory. And it was a long drive between Jerusalem and Haifa with no street lights other than my headlights. And Mobileye failed to detect cars in front of me as consistently as it had during the day. Human-level performance in object detection during the day. Yes! Definitely.
Human-level performance at night with limited lighting. Nope. Still needs work.
And how well did Mobileye work at night when it was raining heavily? In case you didn’t know, rain in Haifa is not like rain in my hometown in Seattle where it’s a gentle drizzle and visibility stays good. In Haifa, it felt like a tropical downpour where buckets of water seemed to be dumped on my car and visibility decreased significantly. Mobileye’s object detection performance dropped to the point that I ignored it completely during the downpour. Admittedly, this is anecdotal experience. But you get the idea that when someone tells you that their AI classifier has achieved human-level performance, you need to ask at least two questions:
- In what narrow task has this model achieved human-level performance? In detecting people, cars and cyclists? Or recognizing faces?
- And in what context? With good lighting? In rainy conditions? At night? During the day?
Why do we care about human-level performance?
For those who drive a Tesla, they trust their driverless car enough to take their hands of the steering wheel to text and drive. That in a nutshell summarizes why we aim for human-level performance. If your model is performing at the level of a driver, it replaces drivers (in certain situations). Or to generalize the benefit, it improves the efficiency of the humans that it replaces i.e., less people are needed to do the work.
For home security cameras using computer vision models to pick up signs of threats, the model acts as a second pair of eyes that flags a human if it detects threats like a person walking onto a home’s front yard at midnight. It also improves productivity i.e., the same people can do a lot more work.
For example, once at Amazon, there was a third party seller who was selling toilet seat covers, bathroom rugs and door mats that had images of Hindu gods, Jesus, the Quranic text and other religious symbols. Insulted, many customers deleted the Amazon app from their phones and started boycott campaigns. This happened multiple times over several years with people arguing that the company only cared about making a profit regardless of religious sensitivities. But to be fair, it is difficult to hire the manpower to police hundreds of millions of product photos daily. But thanks to the power of computer vision model, Amazon built an image classifier that was able to identify if there were religious images plastered on other objects – toilet paper, women’s leggings, doormats – on hundreds of millions of products.
Imagine if people had to be hired to monitor all these photos daily! It would have become a logistic nightmare. But with this religious image classifier, a small team could easily monitor images on hundred of millions of products.
What is your classifier’s gap?
If you’re a CEO, VP, director, manager, product manager, technical program manager or are involved in any type of AI classifiers, you should ask yourself or your scientists one question: what is the gap between my classifier model and human-level performance?
You may think that your science or engineering team will know the answer. But surprisingly, they rely on just precision and recall metrics (see the blog on ‘The Leaky Precision-Recall Funnel’ for more details on this metric). In fact, for one client, for a whole year, we did not know what the human-level performance was and relied on the usual classification metrics: precision, recall, F1-score, AUC (Area under the Curve). That tells you how well your classifier is performing against a development or test set. BUT, and this is a big BUT, it still doesn’t tell you two things:
- How rapidly will your classifier continue to improve? After it crosses the human ceiling (shown in blue), performance improvement rapidly slows down as shown in the graph below (taken from Andrew Ng’s course).
- When will further improvements no longer be possible? That’s when it hits Bayes’ optimal error (shown in green). Before hitting this ceiling, you have avoidable errors that you can minimize.
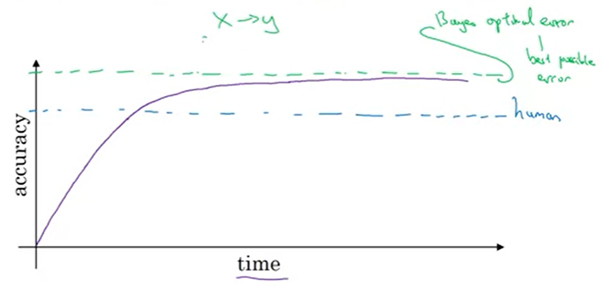
Source: Andrew Ng’s course ‘Structuring Machine Learning Projects’ on Coursera (strongly recommended)
Started in 2006, Inabia is HQ in Redmond, WA. Our main goal is to provide the best solution for our clients across various management and software platforms. Learn more about us at www.inabia.com. We partner with Fortune 100, medium-size and start-ups companies. We make sure our clients have access to our best-in-class project management, staffing and consulting services.
