What is the Bias-Variance Trade-off
- August 17, 2020
- Posted by: admin
- Category: AI

An incorrect idea: The traditional approach to the bias-variance trade-off for AI models was that you can’t lower one metric without raising the other.
What is the bias-variance tradeoff?
In an earlier post, we discussed the three sources of errors in AI (Artificial Intelligence) models such as machine and deep learning: noise, bias and variance. To summarize, bias is the learning error that a model makes during training while variance is the generalization error it makes when classifying data it hasn’t seen before.
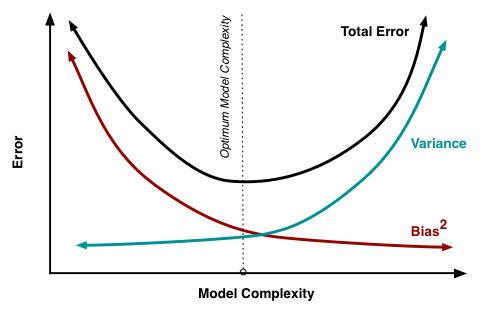
But what is the bias-variance trade-off? This was based on a 1992 study that showed for certain machine learning models, by reducing bias on the training set, eventually the variance on the test set would start increasing (see diagram below). However, several other studies showed that this is only true in a very narrow context i.e., it is true for non-parametrized models such as kNNs and decision trees and under-parametrized neural nets such as shallow neural nets (single hidden layer). With over-parametrized neural nets, the single U-curve dips back downwards for variance resulting in low bias AND variance.
A parameter would be the weights and biases that comprise the multiple linear regression equation for a neuron in a neural net e.g., y = W1x + W2x + W3x + b. In this example, there are four parameters (W1, W2, W3 and b). An over-parametrized neural net would then be a model that has more parameters than data. So for a voice assistant such as Google Home or Siri or Alexa, if there were one million examples in the training set and 10 million parameters in the model trying to understand the question, then this would be an over-parametrized model i.e., 10 million parameters > 1 million data points.
An under-parametrized neural would be where there is more data than parameters e.g., 100 parameters < 1 million data points. And it is these under-parameterized neural nets then that would actually have the bias-variance trade-off: you can’t reduce one without increasing the other. But the over-parametrized neural net would be analogous to having your cake and eating it too: you can reduce both bias and variance.
Appendix: IGNORE
What are the things to do when researching a blog topic?
- Research the title for a blog post using Google’s auto-suggest
- Research the title for a blog post using trends.google.com by comparing two or more titles
- Analyze your competition by looking up the top five Google results for that topic
- Validate that your blog covers the various angles about the topic by checking the questions asked by people around this topics (see questions at the bottom of the Google search results)
- Research the topic by covering top five Google results (but don’t copy)
- Ensure that your blog post addresses the specific question you believe is being searched on google, and put yourself in the shoes of the searcher to ensure you include information she/he would be looking for.
- Record the key bullets to cover in your blog by looking at what other blogs covered
- Create an outline based on the bullets specified
- Flesh out the details
What are some titles around bias and variance?
- Understanding the Bias-Variance Tradeoff
- Gentle Introduction to the Bias-Variance Trade-Off in Machine
- Bias–variance tradeoff – Wikipedia
Who are the competitors for this topics?
- https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning
- https://becominghuman.ai/machine-learning-bias-vs-variance-641f924e6c57
- https://datascience.stackexchange.com/questions/37345/what-is-the-meaning-of-term-variance-in-machine-learning-model
- https://www.mastersindatascience.org/resources/difference-between-bias-and-variance/
- https://medium.com/datadriveninvestor/bias-and-variance-in-machine-learning-51fdd38d1f86
What are some questions commonly asked around bias and variance?
- What is bias and variance?
- What is bias in machine learning?
- What is variance in machine learning?
- Why is Overfitting called high variance?
- How do I know if my data is Overfitting?
- How do you deal with Overfitting and Underfitting?
- How can machine learning reduce bias and variance?
- What is bias and variance in ML?
- Is a high variance good or bad?
- How do you control variance?
- Is variance biased?
- What is variance in ML?
Total error = Unavoidable Bias + Avoidable Bias + Variance
Outline
- The analogy of a parameter is like the synapse or channel between neurons which are the calculators
- There are 100 trillion synapses
- PQC has 60 million parameters
- https://youtu.be/kpiY_LemaTc
- Gpt-3 had 160 billion parameters and cost $4.6 million to train
- Bias is one of three sources of error in machine learning models and occurs because the model made incorrect assumptions during the learning process.
- Variance is controlled by techniques such as regularization which by ordering overfitting allows for better generalization. Or adding more data. Or changing the neural networks architecture
- Reduce bias by increasing the epochs (iterations). Or bigger network (add more layers and or neurons)
- What is regularization? It’s the process of adding more data to prevent overfitting. Overfitting occurs because the model is trying to predict even the noise in the signal. It is a process of regression does this by constraining or regularizing the coefficients in the parameters by reducing then to 0. The net effect if that it prevents the model from becoming too complex and thus prevents overfitting
- Noise are the data points that don’t represent the true properties of the data but rather irrelevant signals. An analogy would be like learning about a country by watching their movies e.g., Hollywood movies to understand American culture or Bollywood movies to understand Indian culture. The impression becomes that there is a high level of crime and violence in the society. Regularization would reduce it discount that information when judging a population
- Variance = validation set error – training set error (draw the difference)
- Bias = Training set error – Human error
- Create practice problems that quantify whether it’s an underfitting problem or an overfitting problem. Is it high bias and low variance or the other way. If variance is greater than bias, then it’s a low bias, high variance problem (overfitting or it’s memorizing the training data and thus not able to generalize). If bias is greater than variance, it’s a high bias, low variance problem (underfitting or failure to learn from the existing problem)
- Bias-variance decomposition of misclassification rates is the most commonly used loss function for supervised learning problems
- Bias tells you that you have a learning problem while variance tells you that you have a generalization problem
- This tool came from sampling theory statistics
- A loss function is also known as a cost function. And this optimization process requires a loss function to calculate the model error. It is used to evaluate how well an algorithm models a given dataset. Goal is to get to 0.
- What other loss function can be used to decompose misclassifications? Quadratic loss function is not appropriate because class labels are not numeric. Zero-one loss function is best for expected mis-classification rate i.e.,1 if classification is correct and 0 if it’s wrong.
- If you want to fit your model to data, traditional statistics state that you should have more data than parameters. Parameters are the Wi and B E.g., 10,000 data points in a network but 1,000,000 parameters. Over parameterized network which is exactly the opposite with deep learning networks which are massively over parameterized. Traditional approach states 10 k data points > parameters. PQC has 60 M parameters vs 185000 data points which is over parameterized
- Overfitting means that estimates of performance on unseen or new data is overly optimistic. A model generalizes worse than expected. One reason for overfitting is including data from a test set. Or overusing a validation set. The analogy is like a student being told the questions and answers before his test
- Error in a classifier can be broken down to bias, variance or noise. Do you have a learning problem, generalization problem or noisy data? Take the right actions to reduce the classifier error. In practice, people will focus on reducing variance when they’re a bigger issue with bias.
- Create practice problem around definitions of bias, variance and noise.
- Practice: which Target shows high bias, low bias, high variance, low variance
- Calculate bias, variance and noise
- Noise could be a data point that athat a data associate classifies one way on one day but then classifies it differently on a different day for example is it a p q on one day and then says it’s not a p q on another day and this could depend on the DA’s mood and feelings on a particular day.humans aren’t always consistent when they classify something they may be consistent let’s say 80% of the time but inconsistent 20% of the time I’ve actually seen a data associate the same data associate classify a data point or a product question one way on one day and then on another day he went in classified it as a nonprofit question
- What is a training, dev and test set?
- What is the bias-variance tradeoff?
- A model with too little capacity cannot learn the training dataset meaning it will underfit, whereas a model with too much capacity may memorize the training dataset, meaning it will overfit or may get stuck or lost during the optimization process.
- A model saturates when no additional data tossed at it improves its performance
- The capacity of a neural network model is defined by configuring the number of nodes (width) and the number of layers (depth). Learning Capacity is the number of functions a model is able to use to map an input to an output. For example, linear regression models have all solutions with degree 1 polynomials. It deals with model complexity.
- https://www.pnas.org/content/116/32/15849.short
- 1992 dogma: the price to pay for low bias is high variance – Geman et all
- This is true for non parameterized methods or algorithms such kNNs (k nearest neighbor) and kernal
- But wider ANNs generalize better
- There have been no papers since 1992 to study if this is true for modern neural networks
- What is novel about alexnet
- Check with three applied scientists to challenge this point
- The classic u-shaped curve (dev error vs learning Capacity (y-axis) for x-axis)
- This trade-off only exists for classification models with a limited learning capacity as indicated by the number of parameters (network width aka number if hidden layers) + training size
- In 2018, a paper was produced that shows that this u-shaped curve only occurs for under parameterized models (small learning capacity – i.e., even if you toss more data at it, learning fails to improve as shown by the variance)
- As the learning capacity (aka parameters) increases, this problem disappears as shown by the double descent curves
- Number of parameters or weights needed = number of classes x sample size e.g., imagenet has 10∆6 images with 10∆3 classes. Parameters needed = 10∆9
- Parameters needed for PQC: 185 k examples x 2 classes
- Variance (dev set error keeps dropping) with more labeled samples while bias drops with model changes and more data
- If variance decreases with increasing width, as shown in the 2018 University of Montreal paper using mnist data, would PQC get better with increasing width but on the same number of Annotations? Even if latency increases, would it work for PQC for annotations or scoring?
- Non parametric models are computationally slower since they make no assumptions. Their structure isn’t pre define e.g., knn. and they use a flexible number of parameters grow as they get more data
- A parametric model has a fixed number of parameters e.g., linear regression
- How do you calculate total error
- For the first goal, achieving human level performance = DA agreement (proxy). But nn performance is a function of two things: data and models.
- Data = training data, dev data, with test data being the gateway to determine if there model is good enough to deploy. Scientists hold the key to the algorithm, architecture, hyperparameters and model training parameters
- For non neural networks such as the vertical classifiers, a test set is still needed to evaluate their performance
- A model with too little capacity cannot learn the training dataset meaning it will underfit, whereas a model with too much capacity may memorize the training dataset, meaning it will overfit or may get stuck or lost during the optimization process. A model saturates when no additional data tossed at it improves its performance
- The capacity of a neural network model is defined by configuring the number of nodes (width) and the number of layers (depth). Learning Capacity is the number of functions a model is able to use to map an input to an output. For example, linear regression models have all solutions with degree 1 polynomials. It deals with model complexity.
- This prevents an impressive machine learning model from becoming a failure in prod
- Multiple reasons for a model not generalizing well is that the training or validation data set was not large enough
- Test set is used once to evaluate the performance. It’s the target to aim for and is measured by variance
- Training, validation and test sets are inconsistently used and need to be defined.
- We see performance curves but not the final bias and variance with the test set. Why is this important when you see precision and recall against a labeled dataset?
- Variance tells us whether the dev set needs to be changed
- All data is inherently noisy meaning that there are datapoints not relevant to the discussion. E.g., salary of people in Medina had several billionaires. And including them in the average salary messes the numbers. Or a house price is not just proportional to the data given: zip code, square footage, etc. It could be a foreign investor ready to overpay on a home
- Noise is not controllable since that’s the limitation of the system. So focusing on bias and variance is the smart approach
- Bias is how well my model can fit the true relationship. Lie complexity has high bias model e.g., a straight line. A simplified model has high bias
- How do you measure bias and variance in a deep learning problem such as PQ classification? Or scoring classifier?
Started in 2006, Inabia is HQ in Redmond, WA. Our main goal is to provide the best solution for our clients across various management and software platforms. Learn more about us at www.inabia.com. We partner with Fortune 100, medium-size and start-ups companies. We make sure our clients have access to our best-in-class project management, staffing and consulting services.
