Aim for Reducing Bias and Variance
- July 28, 2020
- Posted by: admin
- Category: AI

Bulls-eye: What should you do to improve your machine and deep learning models so they hit your target? Use bias and variance to find out
What is the difference between bias and variance?
When working as a technical program manager with both machine learning and deep learning models, the key success criteria that stakeholders review is always precision and recall. While admittedly, these are important metrics, bias and variance should also be evaluated as part of a classification model’s performance. Before understanding why they’re important, let’s first answer the question: what is bias and variance and what is the difference between the two?
Both bias and variance are a measurement of classification error for supervised learning problems. The difference however is that bias is a measurement of error between your model’s prediction and the ground truth in training data while variance is a measurement of error with the ground truth in development or test data.
In other words, bias quantifies the error the model makes in learning while variance quantifies the error made in generalizing the prediction to data it hasn’t seen. Variance thus shows the variability you get when different datasets are used: the better the fit between a model and the cross-validation data, the smaller the variance. The goal is to always have a low bias and low variance model.
| # | Attribute | Bias | Variance |
|---|---|---|---|
| 1 | Used for supervised learning problems | ||
| 2 | Measures classification error | ||
| 3 | Quantifies error using training data | ||
| 4 | Quantifies error using development data | ||
| 5 | Learning error (model failed to learn from data i.e., underfitting) | ||
| 6 | Generalization error (model failed to generalize i.e., overfitting) |
This strategy on teasing out where the error is occurring using these two metrics will help identify the techniques needed to reduce that error and thus reach human-level performance sooner. Failing to take this approach will slow the improvement of a model’s performance as data scientists try different ideas to improve precision and recall. For example, data scientists may feel they need to collect more annotation data which may definitely help but may not help as much as deepening a model’s architecture by adding more hidden layers.
What is the ideal combination?
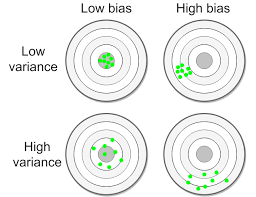
There are four possible combinations of errors with the best scenario listed as # 1 and the worst as #4.
- Low bias and low variance (top left): this is the ideal scenario since your classifier has learned well from the training data and is able to generalize to data it hasn’t seen
- High bias and low variance (top right): model has underfit the training data i.e., has not learned sufficiently from the training data.
- Low bias and high variance (bottom left): most likely, your model has overfit the training the data. Essentially, it’s like a student who memorizes the answers to a math quiz. But because he failed to understand the material, when tested on new math problems, he’s unable to apply what he learned.
- High bias and high variance (bottom right): this is the worst scenario where the model has neither learned sufficiently from the training data and generalizes badly
For example, let’s say you built a classifier that identifies whether you have an image of a cat or a dog. The training data uses a lot of high-resolution images of cats and dogs and the classifier classifies 90% of the images correctly. So the bias is only 10% (100% – 90%). But when the classifier is used with development images that rely on low resolution web images of cats and dogs, it only correctly identifies cats and dogs 70% of the time. Variance is now 20% (90% – 70%). The equations are:
- Bias (with training set of images) = 100% – accuracy with training set = 100% – 90% = 10%
- Variance (with development set of images) = Accuracy with training set – Accuracy with development set = 90% – 70% = 20%
In this example of a cat and dog classifier, since bias is only 10% while variance is 20%, data scientists should focus on variance reduction techniques rather than bias reduction techniques. And this key point answers the question: why isn’t precision and recall enough? The primary reason is that precision and recall clarifies what is performing well while bias and variance tells you where to improve. By focusing your engineering efforts on the areas identified by these metrics, your classifier will achieve human-level performance sooner by building a low bias, low variance model.
Started in 2006, Inabia is HQ in Redmond, WA. Our main goal is to provide the best solution for our clients across various management and software platforms. Learn more about us at www.inabia.com. We partner with Fortune 100, medium-size and start-ups companies. We make sure our clients have access to our best-in-class project management, staffing and consulting services.
